
Kafka, ksqlDB, and Earthquakes
Kafka is a distributed data streaming technology. Kafka Streams and more recently ksqlDB make it easy to build applications that respond immediately to events.
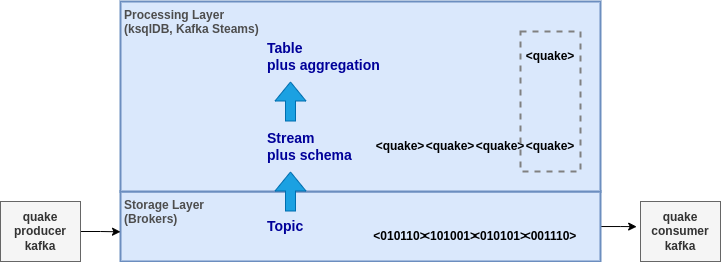
Streams and tables build on top of topics in brokers. Topics live in the storage layer. Streams and tables live in the processing layer. See Streams and Tables in Apache Kafka: A Primer.
In this blog I’m going to walk through my experiment with Kafka and ksqlDB using earthquake location information for New Zealand from GeoNet. You can follow along with the code from https://github.com/gclitheroe/exp. Earthquake location information is a useful data set to experiment with. Earthquake locations evolve as more data arrives so there are many updates. For example for the earthquake 2023p122368 there are 134 updates.
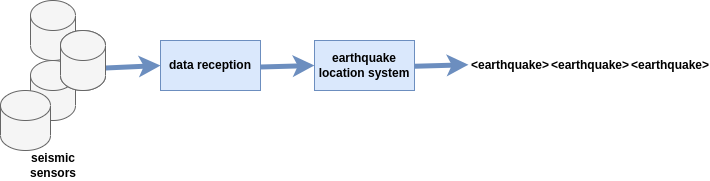
Seismic data is continuously processed by the earthquake location system and as more data arrives new earthquake locations are made available. We will work with these locations (as files on disk), send some to a topic and then spend most of the time using streams and tables in ksqlDB to work with the data.
Setup
Install Go, Docker, and Docker Compose:
- Go https://go.dev/doc/install
- Docker https://docs.docker.com/engine/install/
- Docker Compose https://docs.docker.com/compose/install/
Set up the standard Go directories and clone the code:
mkdir -p $(go env GOPATH)/src/github.com/gclitheroe
cd $(go env GOPATH)/src/github.com/gclitheroe
git clone https://github.com/gclitheroe/exp
cd exp
Bring up the Confluent Kafka platform in Docker (see also ksqlDB Quickstart).
This provides Kafka along with a schema registry and ksqlDB. There is a Docker Compose file in the kafka directory.
docker-compose up -d
Visit the control center at http://localhost:9021/ (it can take a moment to start) navigate to the control center cluster.
Create a topic called quake with protobuf schemas for the key and value. Use protobuf/quake/quake.proto for the value
and protobuf/quake/key.proto. These define the schema for sending and querying quake information.
Send Quake Events
There is demo location information for two earthquakes. These are binary files in protobuf format that matches the schemas
used for the quake topic. The files were created from SeisComPML using cmd/sc3ml2quake. See also Protobufs With Go
In the cmd/quake-producer-kafka dir:
go build
./quake-producer-kafka -input-dir demo-data/2023p007281
./quake-producer-kafka -input-dir demo-data/2023p122368
In the cmd/quake-consumer-kafka dir:
go build
./quake-consumer-kafka
This will echo send and receive information to the terminal. This producer and consumer pattern in the heart of many event driven microservices.
Stop quake-producer-kafka, we don’t need it anymore.
Streams and Tables with ksqlDB
Start the ksqldb-cli container - will use this to interact with ksqlDB via SQL. All the following commands are run at the terminal prompt in this container.
docker exec -it ksqldb-cli ksql http://ksqldb-server:8088
Begin by telling ksqlDB to start all queries from the earliest point in each topic:
SET 'auto.offset.reset'='earliest';
The quake topic is an immutable log of facts with all quake events stored in it. We can materialise this into a mutable
table that has the latest information (the last message sent to Kafka) for each quake using the
CREATE SOURCE TABLE statement. This creates a
materialised view table using the full fact and the schema from the registry. See How to convert a changelog to a table for more information.
CREATE SOURCE TABLE quake_latest (
quake_id STRING PRIMARY KEY
) WITH (
kafka_topic = 'quake',
format = 'protobuf',
value_schema_full_name = 'quake.Quake'
);
This table can be queried. See Operators for dereferencing structs and Scalar functions for working with values.
SELECT public_id,
FORMAT_TIMESTAMP(FROM_UNIXTIME(time->secs * 1000), 'YYYY-MM-DD''T''hh:mm:ss') AS time,
magnitude
FROM quake_latest;
+---------------------------+---------------------------+---------------------------+
|PUBLIC_ID |TIME |MAGNITUDE |
+---------------------------+---------------------------+---------------------------+
|2023p007281 |2023-01-03T04:39:21 |5.109284389 |
|2023p122368 |2023-02-46T06:38:10 |5.976956766 |
We can create a stream from the quake topic using CREATE STREAM. This creates
a stream of data backed by the quake topic. It can be queried and processed using SQL and also
used to materialise additional tables. New operations on the stream start from the beginning (the first event in the underlying topic)
because we earlier set SET 'auto.offset.reset'='earliest';. Any new quake events sent to quake will also appear on the
stream and in any downstream queries or tables.
CREATE STREAM quake_stream (
quake_id STRING KEY
) WITH (
kafka_topic = 'quake',
format = 'protobuf',
value_schema_full_name = 'quake.Quake',
key_schema_full_name = 'quake.Key'
);
The stream can be queried directly although this is query on read and can involve reading all messages in the stream.
select public_id from quake_stream limit 3;
+-------------------------------------------------------------------------------------+
|PUBLIC_ID |
+-------------------------------------------------------------------------------------+
|2023p007281 |
|2023p007281 |
|2023p007281
We can create a table that is updated every time a new event appears on the stream (query on write). This is much faster
to query on read and in this case only contains the latest information for each quake. This is similar to the table we made
earlier with CREATE SOURCE TABLE although it is made from the stream, and we select a smaller set of information. There
has to be a projection over the stream and aggregation on the value fields, in this case GROUP BY and LATEST_BY_OFFSET
see Aggregation functions.
CREATE TABLE quake_latest_from_stream AS
SELECT public_id,
LATEST_BY_OFFSET(time->secs) AS time,
LATEST_BY_OFFSET(magnitude) AS magnitude,
LATEST_BY_OFFSET(depth) AS depth
FROM quake_stream
GROUP BY public_id
EMIT CHANGES;
select * from quake_latest_from_stream;
+-------------------+-------------------+-------------------+-------------------+
|PUBLIC_ID |TIME |MAGNITUDE |DEPTH |
+-------------------+-------------------+-------------------+-------------------+
|2023p007281 |1672763961 |5.109284389 |6.732970715 |
|2023p122368 |1676443090 |5.976956766 |54.28686523 |
If we want a smaller set of information materialised in the table this is easy to do with a WHERE clause:
drop table quake_latest_from_stream;
CREATE TABLE quake_latest_from_stream AS
SELECT public_id,
LATEST_BY_OFFSET(time->secs) AS time,
LATEST_BY_OFFSET(magnitude) AS magnitude,
LATEST_BY_OFFSET(depth) AS depth
FROM quake_stream
WHERE public_id = '2023p122368'
GROUP BY public_id
EMIT CHANGES;
select * from quake_latest_from_stream;
+-------------------+-------------------+-------------------+-------------------+
|PUBLIC_ID |TIME |MAGNITUDE |DEPTH |
+-------------------+-------------------+-------------------+-------------------+
|2023p122368 |1676443090 |5.976956766 |54.28686523 |
It is also easy to create a stream with a smaller set of fields in it. This can be queried and could be used to create other tables.
CREATE STREAM quake_stream_filtered AS
SELECT
quake_id KEY,
time,
magnitude
FROM quake_stream
EMIT CHANGES;
select * from quake_stream_filtered limit 3;
+----------------------------------+----------------------------------+----------------------------------+
|KEY |TIME |MAGNITUDE |
+----------------------------------+----------------------------------+----------------------------------+
|2023p007281 |{SECS=1672763961, NANOS=234110000}|4.942331787 |
|2023p007281 |{SECS=1672763961, NANOS=642158000}|4.977927 |
|2023p007281 |{SECS=1672763961, NANOS=642158000}|5.123278328 |
If you would like to experiment with more data the quake-protobufs release has a tar file
quake-2020.tar.gz. It contains 304510 update files for 22355 earthquakes from New Zealand from the year 2020.
Download and extract this file and then run:
quake-producer-kafka path.../quake-2020
We’re done. Exit ksql-cli ctrl-d and stop the cluster docker-compose down.
Kafka and ksqlDB provide an easy and powerful way to build streaming applications, bring together the power of streams and database tables.
The New Zealand GeoNet programme and its sponsors EQC, GNS Science, LINZ, NEMA and MBIE are acknowledged for providing data used in this repo. GeoNet doesn’t use Kafka although it does do a lot of data streaming.